Taxonomien ermöglichen eine andere Sicht auf Informationen in Ihrem Content Server-Repository und können somit die Navigation von und Suche nach Informationen erleichtern. Eine gut definierte, richtig implementierte Unternehmens-Taxonomie steigert die Produktivität, da Content Server-Benutzer die Informationen, die Sie für bestimmte Aufgaben benötigen, ganz einfach finden können.
Für ein einfaches Durchsuchen sind Taxonomien als Baumstrukturen angeordnet. Am Fuß der Baumstruktur stehen weitgefasste Klassifikationen. Je weiter Sie die Äste des Baumes verfolgen, desto spezifischer werden die Klassifikationen.
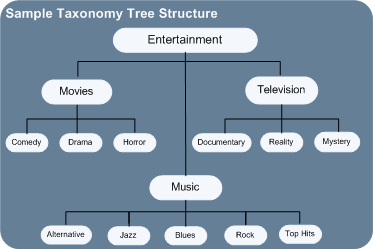
Taxonomien erstellen
Es gibt drei häufig verwendete Ansätze bei der Erstellung von Taxonomien: automatisch, unterstützt und professionell. Den geeigneten Ansatz wählen Sie basierend auf den Fähigkeiten des Taxonomie-Erstellers und auf den geschäftlichen Anforderungen Ihres Unternehmens.
-
Bei der automatischen Taxonomie-Erstellung werden Objekte gruppiert und diese Gruppen anhand statistischer Modelle in Taxonomien angeordnet. Bei diesem Ansatz ist nur ein einziger Schritt nötig, um die Taxonomie zu erstellen und die Objekte zu kategorisieren.
-
Die unterstützte Taxonomie-Erstellung erfordert einen Knowledge Manager oder Bibliothekar, der die Taxonomie-Erstellung überwacht und überprüft, Alternativen vorschlägt und Kategorien interaktiv und iterativ korrigiert. Die unterstützte Taxonomie-Erstellung ermöglicht mehr Präzision und Kontrolle über den Kategorisierungsprozess, erfordert aber eine spezielle Ressource.
-
Die professionelle Taxonomie-Erstellung wird von vielen Drittanbietern ausgeführt und bietet Unternehmen eine hochwertige Kategorisierung. Für Records-Management-Anwendungen ist dies der geeignete Ansatz.
Objekte klassifizieren
-
Bei der automatischen Klassifikation werden Regeln oder Profile erstellt, die die Klassifikation(en) vorgeben, in die ein bestimmtes Objekt klassifiziert werden soll. Dieser Ansatz erfordert kein Eingreifen durch einen Knowledge Manager oder Bibliothekar.
-
Die unterstützte Klassifikation erfordert einen Knowledge Manager oder Bibliothekar, der die Klassifikation überwacht und überprüft, Alternativen vorschlägt und Klassifikationen interaktiv und iterativ korrigiert. Die unterstützte Klassifikation ist der am häufigsten verwendete Ansatz, da sie mehr Präzision und Kontrolle über den Klassifikationsprozess ermöglicht.
-
Die manuelle Kategorisierung erfordert die explizite Klassifikation jedes Objekts, das zum Repository hinzugefügt wird, durch einen Benutzer. In stark regulierten Umgebungen, z. B. beim Militär, ist dies der einzige akzeptable Ansatz.